
We don’t need ML, we have gzip!
Posted 7/15/2023
A recent excellent paper performs a sophisticated natural language processing task, usually solved using complicated deep-learning neural networks, using a shockingly simple algorithm and gzip. This post will contextualize and explain that paper for non-computer scientists, or for those who do not follow news in NLP and machine learning.
What is Text Classification?
Text Classification is a common task in natural language processing (NLP). Here’s an example setting:
Provided are several thousand example questions from Yahoo! Answers, pre-categorized into bins like ‘science questions,’ ‘health questions,’ and ‘history questions.’ Now, given an arbitrary new question from Yahoo! Answers, which category does it belong in?
This kind of categorization is easy for humans, and traditionally much more challenging for computers. NLP researchers have spent many years working on variations of this problem, and regularly host text classification competitions at NLP conferences. There are a few broad strategies to solving such a task.
Bag of Words Distance
One of the oldest computational tools for analyzing text is the Bag of Words model, which dates back to the 1950s. In this approach, we typically discard all punctuation and capitalization and common “stop words” like “the,” “a,” and “is” that convey only structural information. Then we count the number of unique words in a sample of text, and how many times each occur, then normalize by the total number of words.
For example, we may take the sentence “One Ring to rule them all, One Ring to find them, One Ring to bring them all, and in the darkness bind them” and reduce it to a bag of words:
{
'one': 0.27,
'ring': 0.27,
'rule': 0.09,
'find': 0.09,
'bring': 0.09,
'darkness': 0.09,
'bind': 0.09
}
We could then take another passage of text, reduce it to a bag of words, and compare the bags to see how similar the word distributions are, or whether certain words have much more prominence in one bag than another. There are many tools for performing this kind of distribution comparison, and many ways of handling awkward edge cases like words that only appear in one bag.
The limitations of bags of words are obvious - we’re destroying all the context! Language is much more than just a list of words and how often they appear: the order of words, and their co-occurrence, conveys lots of information, and even structural elements like stop words and punctuation convey some information, or we wouldn’t use them. A bag of words distills language down to something that basic statistics can wrestle with, but in so doing boils away much of the humanity.
Word Embeddings
Natural Language Processing has moved away from bags of words in favor of word embeddings. The goal here is to capture exactly that context of word co-occurrence that a bag of words destroys. For a simple example, let’s start with Asimov’s laws of robotics:
A robot may not injure a human being or, through inaction, allow a human being to come to harm. A robot must obey orders given it by human beings except where such orders would conflict with the First Law. A robot must protect its own existence as long as such protection does not conflict with the First or Second Law
Removing punctuation and lower-casing all terms, we could construct a window of size two, encompassing the two words before and after each term as context:
| Term | Context |
|---|---|
| robot | a, may, not, harm, must, obey, law, protect |
| human | injure, a, being, or, allow, to, it, by, except |
| orders | must, obey, given, it, where, such, would, conflict |
| … | … |
This gives us a small amount of context for each term. For example, we know that “orders” are things that can be “obeyed,” “given,” and may “conflict.” You can imagine that if we used a larger corpus for training, such as the complete text of English Wikipedia, we would get a lot more context for each word, and a much better sense of how frequently words appear in conjunction with one another.
Now let’s think of each word as a point in space. The word “robot” should appear in space close to other words that it frequently appears near, such as “harm,” “obey,” and “protect,” and should appear far away from words it never co-occurs with, such as “watermelon.” Implicitly, this means that “robot” will also appear relatively close to other words that share the same context - for example, while “robot” does not share context with “orders,” both “orders” and “robot” share context with “obey,” so the words “robot” and “orders” will not be too distant.
This mathematical space, where words are points with distance determined by co-occurrence and shared context, is called an embedding. The exact process for creating this embedding, including how many dimensions the space should use, how much context should be included, how points are initially projected into space, how words are tokenized, whether punctuation is included, and many finer details, vary between models. For more details on the training process, I recommend this Word Embedding tutorial from Dave Touretzky.
Once we have an embedding, we can ask a variety of questions, like word association: kitten is to cat as puppy is to X? Mathematically, we can draw a vector from kitten to cat, then transpose that vector to “puppy” and look for the closest point in the embedding to find “dog.” This works because “cat” and “dog” are in a similar region of the embedding, as they are both animals, and both pets. The words “kitten” and “puppy” will be close to their adult counterparts, and so also close to animal and pet associations, but will additionally be close to youth terms like “baby” and “infant”.
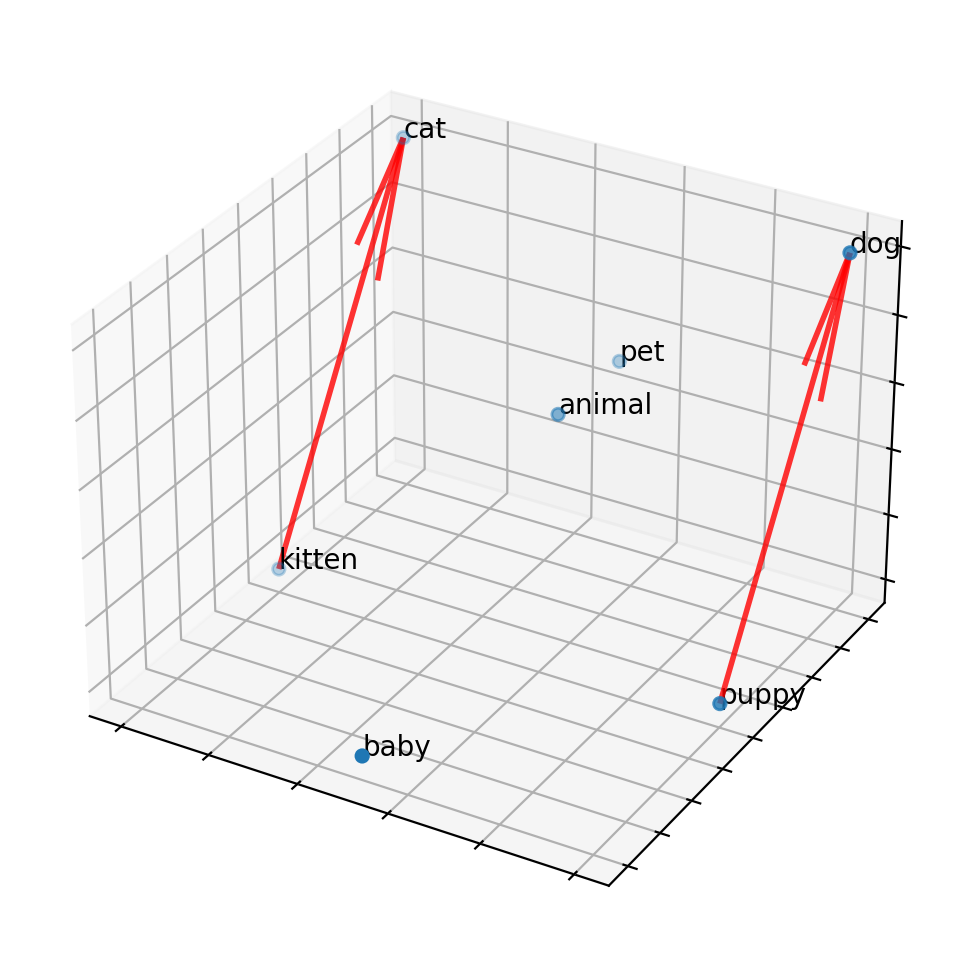
(Note that these embeddings can also contain undesired metadata: for example, “doctor” may be more closely associated with “man” than “woman”, and the inverse for “nurse”, if the training data used to create the embedding contains such a gender bias. Embeddings represent word adjacency and similar use in written text, and should not be mistaken for an understanding of language or a reflection of the true nature of the world.)
In addition to describing words as points in an embedding, we can now describe documents as a series of points, or as an average of those points. Given two documents, we can now calculate the average distance from points in one document to points in another document. Returning to the original problem of text classification, we can build categories of documents as clouds of points. For each new prompt, we can calculate its distance from each category, and place it in the closest category.
These embedding techniques allow us to build software that is impressively flexible: given an embedded representation of ‘context’ we can use vectors to categorize synonyms and associations, and build machines that appear to ‘understand’ and ‘reason’ about language much more than preceding Bag of Words models, simple approaches at representing context like Markov Chains, or attempts at formally parsing language and grammar. The trade-off is that these models are immensely complicated, and require enormous volumes of training data. Contemporary models like BERT have hundreds of millions of parameters, and can only be trained by corporations with vast resources like Google and IBM.
The State of the Art
In modern Natural Language Processing, deep neural networks using word embeddings dominate. They produce the best results in a wide variety of tasks, from text classification to translation to prediction. While variations between NLP models are significant, the general consensus is that more parameters and more training data increase performance. This focuses most of the field on enormous models built by a handful of corporations, and has turned attention away from simpler or more easily understood techniques.
Zhiying Jiang, Matthew Y.R. Yang, Mikhail Tsirlin, Raphael Tang, Yiqin Dai, and Jimmy Lin, did not use a deep neural network and a large embedding space. They did not use machine learning. They used gzip.
Their approach is simple: compression algorithms, like gzip, are very good at recognizing patterns and representing them succinctly. If two pieces of text are similar, such as sharing many words, or especially entire phrases, then compressing the two pieces of text together should be quite compact. If the two pieces of text have little in common, then their gzipped representation will be less compact.
Specifically, given texts A, B, and C, if A is more similar to B than C, then we can usually expect:
1
len(gzip(A+B)) - len(gzip(A)) < len(gzip(A+C)) - len(gzip(A))
So, given a series of pre-categorized texts in a training set, and given a series of uncategorized texts in a test set, the solution is clear: compress each test text along with each training text to find the ‘distance’ between the test text and each training text. Select the k nearest neighbors, and find the most common category among them. Report this category as the predicted category for the test text.
Their complete algorithm is a fourteen line Python script:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import gzip
import numpy as np
for (x1,_) in test_set:
Cx1 = len(gzip.compress(x1.encode()))
distance_from_x1 = []
for (x2,_) in training_set:
Cx2 = len(gzip.compress(x2.encode())
x1x2 = " ".join([x1,x2])
Cx1x2 = len(gzip.compress(x1x2.encode())
ncd = (Cx1x2 - min(Cx1,Cx2)) / max (Cx1,Cx2)
distance_from_x1.append(ncd)
sorted_idx = np.argsort(np.array(distance_from_x1))
top_k_class = training_set[sorted_idx[:k], 1]
predict_class = max(set(top_k_class), key = top_k_class.count)
Shockingly, this performs on par with most modern NLP classifiers: it performs better than many for lots of common English classification data sets, and on most data sets it performs above average. BERT has higher accuracy on every data set, but not by much. A fourteen line Python script with gzip in lieu of machine learning performs almost as well as Google’s enormous embedded deep learning neural network. (See table 3 in the original paper, page 5)
A more recent variant on the classification challenge is to classify text in a language not included in the training data. For example, if we expended enormous resources training BERT on English text, is there any way to pivot that training and apply that knowledge to Swahili? Can we use embeddings from several languages to get some general cross-language fluency at text categorization in other languages? Or, if we do need to re-train, how little training data can we get away with to re-calibrate our embeddings and function on a new language? This is unsurprisingly a very difficult task. The gzip classifier outperformed all contemporary machine learning approaches that the authors compared to. (See table 5 in the original paper, page 6)
Conclusions
This paper is a great reminder that more complicated tools, like ever-larger machine-learning models, are not always better. In particular, I think their approach hits upon an interesting balance regarding complexity. Bag of words models discard context and punctuation, making computation simple, but at the cost of destroying invaluable information. However, keeping all of this information in the form of an embedding, and attempting to parse human language, incurs a heavy complexity cost. There’s a lot of “fluff” in language that we do not necessarily need for classification. The gzip approach keeps the extra context of word order and punctuation, but does not try to tackle the harder problem of understanding language in order to address the simpler problem of looking for similarities. In general, tools should be as simple as possible to complete their task, but no simpler.
EDIT 7/18/2023 - Misleading Scores in Paper
It appears that the authors have a made an unusual choice in their accuracy calculations, which inflate their scores compared to contemporary techniques. In summary, they use a kNN classifier with k=2, but rather than choosing a tie-breaking metric for when the two neighbors diverge, they mark their algorithm as correct if either neighbor has the correct label. This effectively makes their accuracy a “top 2” classifier rather than a kNN classifier, which misrepresents the performance of the algorithm. This isn’t necessarily an invalid way to measure accuracy, but it does need to be documented, and isn’t what we’d expect in traditional kNN. The gzip scores under a standard k=2 kNN remain impressive for such a simple approach and are still competitive - but they’re no longer beating deep neural network classifiers for non-English news datasets (table 5).
Here’s the problem in a little more detail:
-
The authors compress all training texts along with the test prompt, to find the gzip distance between the prompt and each possible category example
-
Rather than choosing the closest example and assuming the categories match, the authors choose the
kclosest examples, take the mode of their categories, and predict that. This k-nearest-neighbors (kNN) strategy is common in machine learning, and protects against outliers -
When the number of categories among neighbors are tied, one must have a tie-breaking strategy. A common choice is to pick the tie that is a closer neighbor. Another choice might be to expand the neighborhood, considering one additional neighbor until the tie is broken - or inversely, to shrink the neighborhood, using a smaller k until the tie is broken. Yet another choice might be to randomly choose one of the tied categories.
-
The authors use
k=2, meaning that they examine the two closest neighbors, which will either be of the same category, or will be a tie. Since they will encounter many ties, their choice of tie-breaking algorithm is very important -
In the event of a tie between two neighbors, the authors report success if either neighbor has the correct label
The code in question can be found here. Further analysis by someone attempting to reproduce the results of the paper can be found here and is discussed in this GitHub issue. In conversations with the author this appears to be an intentional choice - but unfortunately it’s one that makes the gzip classifier appear to outperform BERT, when in reality if it gives you two potentially correct classes and you always pick the correct choice you will outperform BERT.
I’ve heard the first author is defending their thesis tomorrow - Congratulations, good luck, hope it goes great!