
Distinguishing In-Groups from Onlookers by Language Use
Posted 6/8/2022
This post is a non-academic summary of my most recent paper, which can be found here. It’s in a similar theme as a previous paper, which I discussed here, but this post can be read on its own. An enormous thank you to my fantastic co-authors Josh Minot, Sam Rosenblatt, Guillermo de Anda Jáuregui, Emily Moog, Briane Paul V. Samson, Laurent Hébert-Dufresne, and Allison M. Roth.
If you wanted to find QAnon believers on Twitter, YouTube, or Reddit, you might search for some of their flavorful unique vocabulary like WWG1WGA (“Where we go one, we go all”). To find cryptocurrency enthusiasts, you might search for in-group phrases like HODL or WAGMI, or “shitcoins”, or specific technologies like “NFT” or “ETH”. This works well for new, obscure communities, when no one else has picked up on their vocabulary. However, once a community reaches the limelight, the keyword-search strategy quickly deteriorates: a search for “WWG1WGA” is now as likely to find posts discussing QAnon, or ridiculing them, as it is to identify true believers.
Human observers with some contextual understanding of a community can quickly distinguish between participants in a group, and discussion about (or jokes about) a group. Training a computer to do the same is decidedly more complicated, but would allow us to examine exponentially more posts. This could be useful for tasks like identifying covid conspiracy communities (but distinguishing them from people talking about the conspiracists) or identifying a hate group (but distinguishing from people discussing hate groups). This, in turn, could help us to study the broad effects of deplatforming, by more systematically examining where communities migrate when they’re kicked off a major site. Those possibilities are a long way off, but distinguishing participants in a group from onlookers talking about the group is a step towards the nuance in language processing we need.
Setup
Our study focuses on a simple version of this problem: given a subreddit representing an in-group, and a subreddit dedicated to discussing the in-group, automatically label commenters as being part of the in-group or onlookers based on the text of their comments. We use the following list of subreddit pairs:
| In-Group | Onlooker | Description |
|---|---|---|
| r/NoNewNormal | r/CovIdiots | NoNewNormal discussed perceived government overreach and fear-mongering related to Covid-19 |
| r/TheRedPill | r/TheBluePill | TheRedPill is part of the “manosphere” of misogynistic anti-feminist communities |
| r/BigMouth | r/BanBigMouth | Big Mouth is a sitcom focusing on puberty; BanBigMouth claimed the show was associated with pedophilia and child-grooming, and petitioned for the show to be discontinued |
| r/SuperStraight | r/SuperStraightPhobic | SuperStraight was an anti-trans subreddit, SuperStraightPhobic antagonized its userbase and content |
| r/ProtectAndServe | r/Bad_Cop_No_Donut | ProtectAndServe is a subreddit of verified law-enforcement officers, while Bad_Cop_No_Donut documents law enforcement abuse of power and misconduct |
| r/LatterDaySaints | r/ExMormon | LatterDaySaints is an unofficial subreddit for Mormon practitioners, while ExMormon hosts typically critical discussion about experiences with the church |
| r/vegan | r/antivegan | Vegan discusses cooking tips, environmental impact, animal cruelty, and other vegan topics. AntiVegan is mostly satirical, making fun of “vegan activists” |
Some of these subreddit pairs are directly related: r/TheBluePill is explicitly about r/TheRedPill. Other subreddit pairs are only conceptually connected: r/Bad_Cop_No_Donut is about law enforcement, but it’s not specifically about discussing r/ProtectAndServe. This variety should help illustrate under what conditions we can clearly distinguish in-groups from onlookers.
For each subreddit pair, we downloaded all comments made in each subreddit during the last year in which they were both active. In other words, if one or both subreddits have been banned, we grab the year of comments leading up to the first ban. If both subreddits are still active, we grab the comments from the last 365 days to present.
We discarded comments from bots, and comments from users with an in-subreddit average karma below one. This is to limit the effect of users from an onlooking subreddit “raiding” the in-group subreddit (or vice versa), and therefore muddying our understanding of how each subreddit typically writes.
What’s in the Data
Next, we want to identify the words used far more in the in-group than the onlooking group, or vice versa. There are a variety of ways of measuring changes in word-usage, including rank turbulence divergence (which words have changed the most in terms of their order of occurrence between one dataset and another) and Jensen-Shannon divergence (the difference in word frequency between each subreddit and a combination of the two subreddits).
For example, here’s a plot illustrating which words appear more prominently in r/NoNewNormal or r/CovIdiots, based on the words “rank”, where rank 1 is the most used word, and rank 10,000 is the 10,000th most-used word:
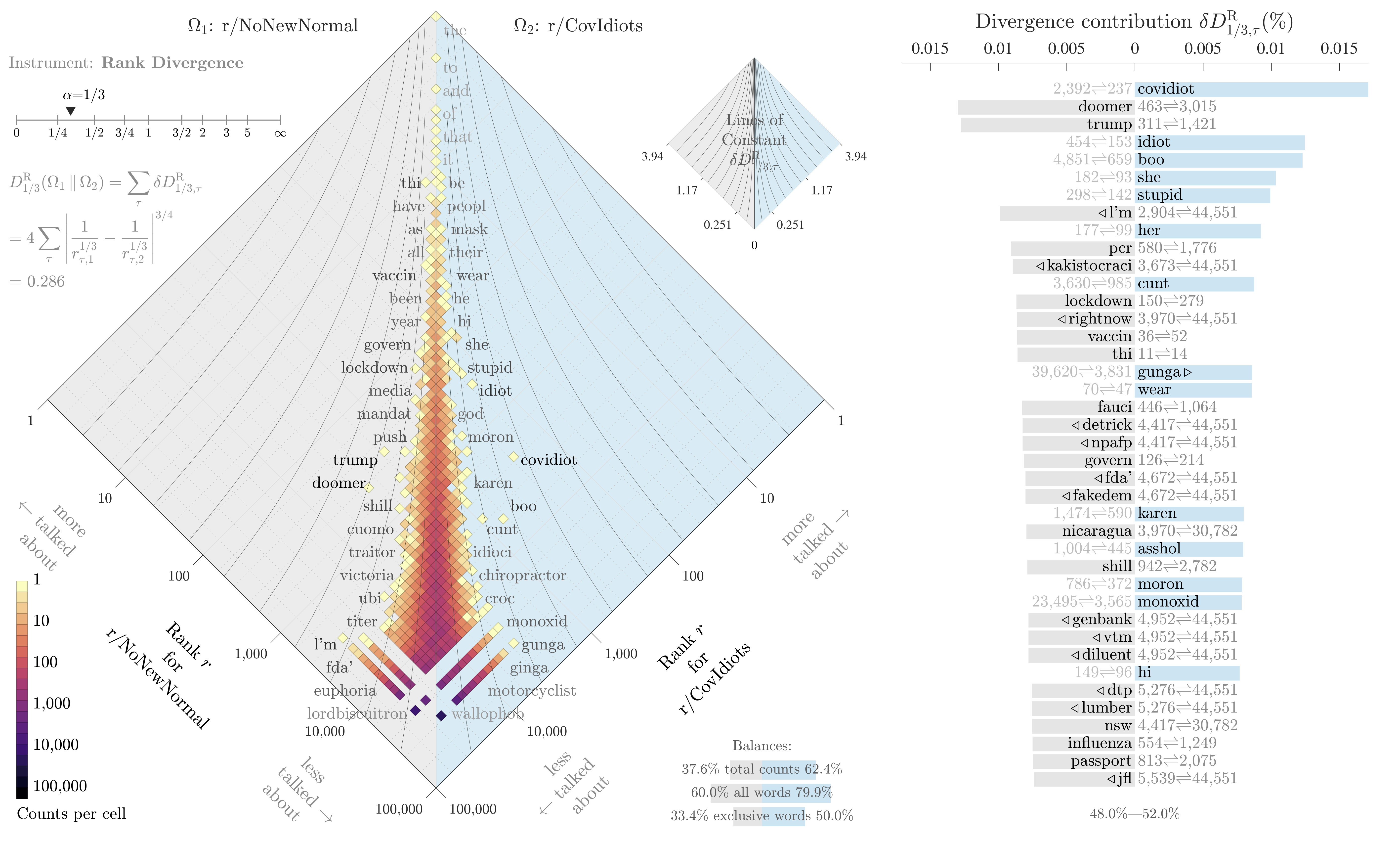
While we know both subreddits feature terms like “vaccine”, “mask”, and “covid”, this plot tells us that terms like “doomer”, “trump”, and “lockdown” are used disproportionately in our in-group, while disparaging terms like “idiot”, “stupid”, and “moron” are far more common in the onlooker group.
We can already see one limitation of this study: the most distinguishing term between our two subreddits is “covidiot”, a term developed on r/CovIdiots. We’re not just capturing some context around the in-group’s use of terminology, we’re identifying keywords specific to this community of onlookers, too.
Building a Classifier
Now that we’ve had a peek at the data, and have confirmed that there are terms that strongly distinguish one community from its onlookers, we want to build a classifier around these distinguishing terms. Specifically, for every user we want to get a big text string consisting of all of their comments, the classifier should take this comment string as input, and return whether the user is in the in-group or the onlooker group.
Since we know whether each user participates mostly in the in-group subreddit, or the onlooking subreddit, we’ll treat that as ground-truth to measure how well our classifier performs.
We built two classifiers: a very simple linear-regression approach that’s easy to reverse-engineer and examine, and a “Longformer” transformer deep-learning model that’s much closer to state-of-the-art, but more challenging to interrogate. This is a common approach that allows us to examine and debug our results using our simple method, while showing the performance we can achieve with modern techniques.
We trained the linear regression model on term frequency-inverse document frequency; basically looking for words common in one subreddit and uncommon in another, just like in the plot above. We configured the Longformer model as a sequence classifier; effectively “given this sequence of words, classify which subreddit they came from, based on a sparse memory of prior comments from each subreddit.”
Results
Here’s our performance on a scale from -1 (labeled every user incorrectly) to 0 (did no better than proportional random guessing) to 1 (labeled every user correctly):
| In-Group | Onlooker | Logistic Regression Performance | Longformer Performance |
|---|---|---|---|
| r/NoNewNormal | r/CovIdiots | 0.41 | 0.48 |
| r/TheRedPill | r/TheBluePill | 0.55 | 0.65 |
| r/BigMouth | r/BanBigMouth | 0.64 | 0.80 |
| r/SuperStraight | r/SuperStraightPhobic | 0.35 | 0.43 |
| r/ProtectAndServe | r/Bad_Cop_No_Donut | 0.50 | 0.55 |
| r/LatterDaySaints | r/ExMormon | 0.65 | 0.72 |
| r/vegan | r/antivegan | 0.49 | 0.56 |
Or, visually:
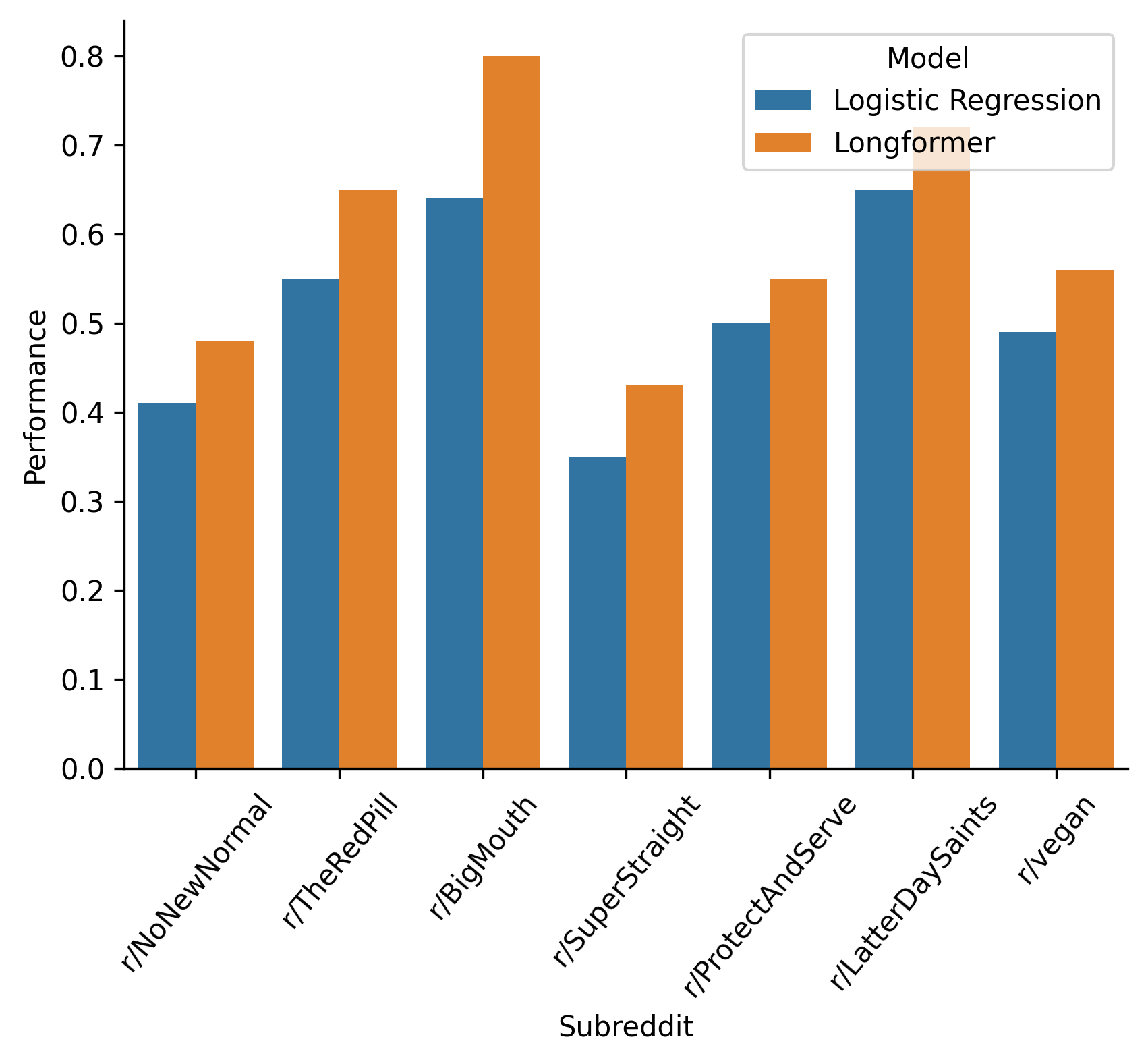
Much better than guessing in all cases, and for some subreddits (BigMouth, LatterDaySaints, and TheRedPill) quite well!
If a user has barely commented, or their comments all consist of responses like “lol”, classification will be near-impossible. Therefore, we can re-run our analysis, this time only considering users who have made at least ten comments, with at least one hundred unique words.
| In-Group | Onlooker | Logistic Regression Performance | Longformer Performance |
|---|---|---|---|
| r/NoNewNormal | r/CovIdiots | 0.57 | 0.60 |
| r/ProtectAndServe | r/Bad_Cop_No_Donut | 0.65 | 0.76 |
| r/LatterDaySaints | r/ExMormon | 0.80 | 0.83 |
| r/vegan | r/antivegan | 0.65 | 0.72 |
And visually again:
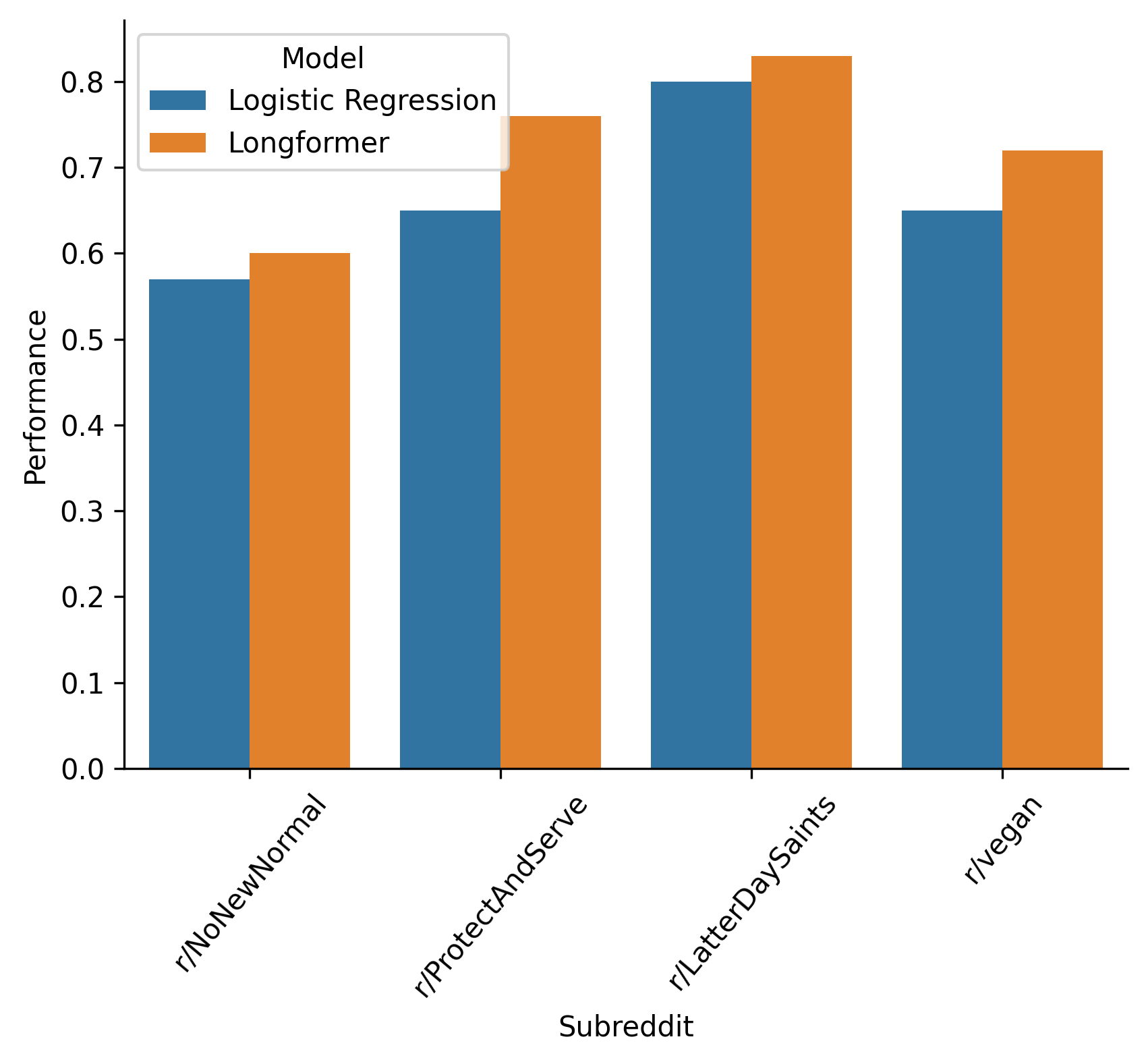
For a few subreddit pairs, the onlooking subreddit has too few comments left over after filtering for analysis to be meaningful. For the four pairs that remain, performance improves significantly when we ignore low-engagement users.
Similarly, we can examine what kinds of users the classifier labels correctly most-often:
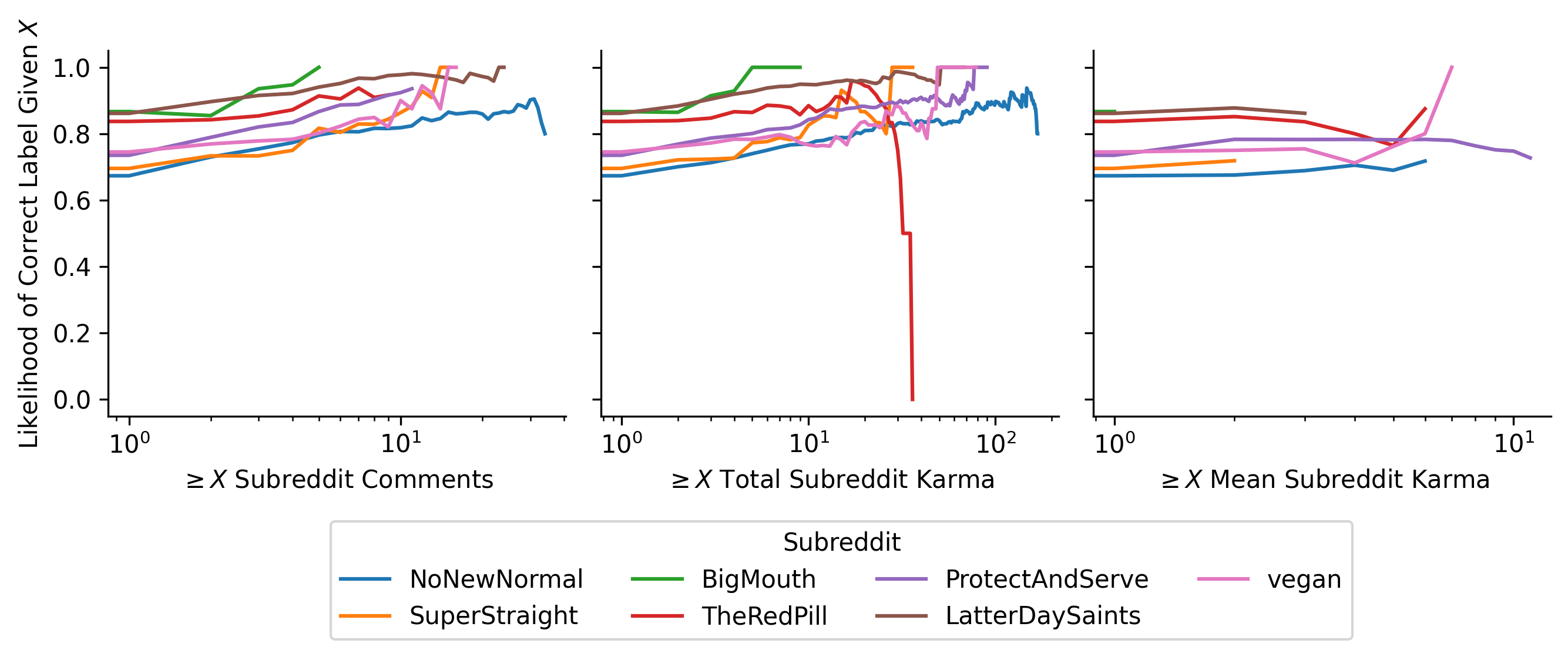
The classifier performs better on users with more comments (and therefore more text to draw from), and more karma in the subreddit (which typically correlates with number of comments unless the user is immensely unpopular), but does not significantly differ with mean subreddit karma. In other words, popular users who receive lots of karma on many of their comments, and therefore might be more representative of the subreddit’s views, are not easier to classify.
Conclusions, Limitations, Next Steps
For a first attempt at solving a new problem, we have some promising results. We can consistently distinguish users from an in-group and users from a specific onlooking group, based on the language of users’ posts. Our study focuses on subreddits, which provide a best-case scenario for classification: comments are neatly partitioned into the in-group and onlooker subreddits. If we studied Twitter users, for example, we’d have no baseline to determine whether our classifier was guessing correctly, or even a good way to feed it training data, without human annotators labeling thousands of Twitter accounts by hand.
It’s also unclear how well this classifier would function in a cross-platform environment. For example, could we train the classifier on a subreddit, and then classify Twitter or Discord users based on their comments? Theoretically, the same community will discuss the same topics on multiple platforms, likely with similar keywords. However, the design of each platform (such as the short character limits on Tweets) may constrain authors enough to make classification harder.
Finally, it’s unclear how well this classification will hold up over time. Would a classifier trained on last year’s comments still perform well on users from this year? Or will the discussion topics of a community have drifted too far for those old word frequencies to be useful? This could be especially important when communities migrate between platforms, when we may for example have old Reddit data and new Discord data.
Lots more to do, but I’m excited about these first steps!